Thank you for checking my projects out. You can find more details of my projects including data, code, documentations and etc on my Github page. Please feel free to send me messages here or shoot me an email if you have any questions about these projects.
Predictive Modeling on Online Students Quiz Performance
This project aims to improve a predictive model of students’ progress in an online course program by adding learned features from unstructured text data. It is still in progress, and all code and relevant work will be pushed to this GitHub page.
Algorithms for Climate Data Sonification
Introduction
Data visualization is the most commonly used approach to analyze and present data. However, patterns, anomalies, or relationships between variables in large and complex datasets may not show up clearly in even the most sophisticated graph. For example, climate time series such as daily temperature data contain information on long-term trends, seasonal variation, localized weather events, and possible measurement or recording errors. It is difficult to design graphs that adequately represent all of these features. My goal of this project is to use sonification to highlight these different features in the dataset to enhance simultaneous graphical explorations.
With the help of my advisor Dr. Mark Greenwood and Dr. Stephen Durbin, I produced a sonification of Bozeman climate data using R shiny. The feedbacks from Dr. Stacey Hancock and my colleagues in Statistical Consulting and Research Services center helped me modify the sonification. In this blog, I will briefly describe the process and the tools that I used for this project.
Data preparation and trend modeling
The dataset that I used for this project is Bozeman maximum monthly temperature from January 1900 to November 2015, which consists of four variables (station, station name, date and maximum monthly temperature). As we can see from Figure 1, there are a few missing months.
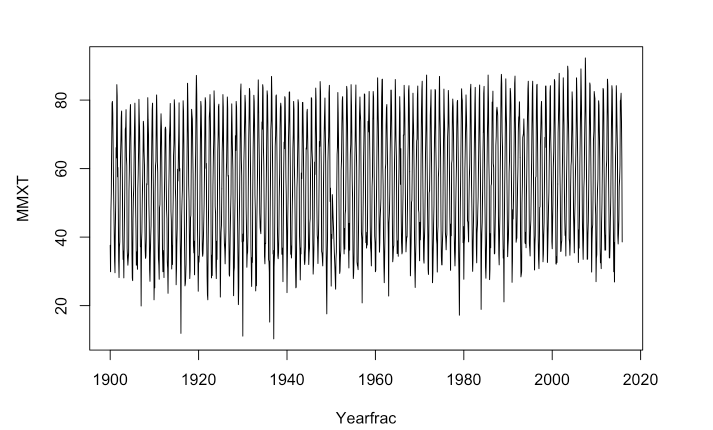
I used ts (time series) function in R to complete the year fraction of each month in the dataset, other data manipulations can be found in my code. Then I used a generalized additive model to fit a model for the trends of the temperature. Generalized additive model is a method that describes the relationship between a univariate response variable, for example, maximum monthly temperature and some predictor variables such as yearly trends and monthly trends of temperature using smooth functions. The model is stated as below:
g(E(MMXT)) = ß0 + f1(YearlyTrend) + f2(MonthlyTrend) + Residuals.
I used the mgcv package in R to build this model, and it explains 93.6% of the deviances of the data. Here is the model summary:
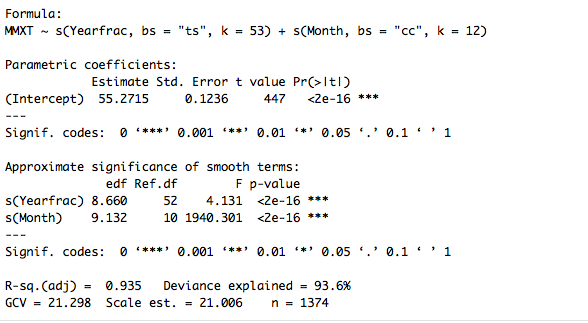
The plot of yearly trends and monthly trends below (Figure 3) suggests that overall, the temperature is estimated to increase by about 4 Fahrenheit degrees over last 115 years, and there continues an increasing trend for the temperature in Bozeman. The monthly trends show that there is a seasonal pattern in the temperature in the data.

Along with long-term trend and seasonal components in the model, I also included the residuals from the model. After building this model, I created a data frame using the values of the model and make it ready for data sonification.
Sonify data
My first approach is to find some R sonification packages and try to build my own sonification package in R. During this process, I found audiolyzeR, sonify, and audio packages in R. These packages can sonify the data, and some sound parameters can be changed in the functions, however, none of them can synthesize different sounds.
After consulting with Dr. Stephen Durbin, I decided to use web audio API to sonify the data. In order to visualize the data while playing the sound, I created R shiny app to show the yearly trends, monthly trends and residuals while the data are sonified. In order to sonify these sounds, I first linearly transformed the yearly trends, monthly trends and residuals into frequencies. I made three different ranges of the frequencies of these three different components of temperature in order to make the sounds of each component distinct from each other, and they are all in one octave.
The monthly trend has the lowest frequency (220 to 440 Hz) because the seasonal trends are pretty constant and systematic, whereas the residuals have the highest frequency (1046.50 to 2093.00 Hz) because of more rapid and frequent changes. The yearly trends have the middle range from 493.88 to 987.77 Hz. Then I used three different instruments to play these three components: grand piano for monthly trend, alto flute for yearly trend and harp for residuals. The audio file of the data sonification can be found here:
The R shiny app is still in the developing process because I want to add more features. However, the data, R code, R shiny app code can be found on my GitHub page.
Study & Analysis of Household WiFi Speed
I conducted a balanced three-factor factorial study to test the main effects of obstacles, a number of WiFi users, the distance between WiFi router and WiFi users, as well as the potential effects of interactions among these three variables on WiFi speed. Then I used SAS to analyze the data.
Full Article: PDF
Presentation: PPT
Code: GitHub
Policy Memo on Fed Policy on Increasing the Threshold for Bank Merger Assets
This policy memo describes the background of how small but complex banks play an important role in the U.S. financial system. What the Fed did recently affect the financial system. Then, I suggest a question for John Delaney (the Joint Economic Committee (JEC) member) to ask and discuss what information they can learn from Chair Yellen’s answers.
Full Article: PDF
Financial Health of United States Banks in 2016
This study reports a k-means clustering analysis investigating patterns of the financial health of all 5,870 banks in the United States in 2016 by using five key variables: net interest margin, return on assets, net charge-offs to loans, tier 1 capital ratio, and total risk-based capital ratio. The results suggest that there are nine groups of banks in terms of their financial health. 1,224 banks are found be in the cluster that represented the most unhealthy institutions, whereas only 19 banks are in the cluster described as most healthy. The banks that failed in the first quarter of 2017 are all found in the first cluster.
Full Article: PDF
Code: GitHub
Slides: PPT
Monsanto’s Influences and Inspirations on Development of China Corn Seeds Companies
This paper will introduce the history and present situation of corn seeds companies in China at first and analyze the opportunities and challenges occurred during the development of corn seeds industries. Then conclude my suggestions on corn seeds companies in China after an analysis of how Monsanto does its business of corn seeds. This is my undergraduate thesis for my bachelor degree from FAFU. I finished it under the instructions from my advisor Professor Liu in May 2016.
Full Article: PDF (written in Chinese)
Effectiveness of NEPs
This paper conducts a differences-in-differences Analysis to find out the effect of starts dates of NEPs in New York State, New Mexico and Massachusetts on drug overdose deaths and HIV/AIDS-related health outcomes, and then analyze the effectiveness of needle exchange programs in these three states. I wrote this paper with the help of Dr. Swensen for my ECNS 490R class in the summer session of 2015.
Full Article: PDF
Conditional Probability and Information Retrieval
This paper discusses about the concept conditional probability and how software engineers use conditional probability to speed mining of interesting phrases in a database.
Full Article: PDF
Math & Music
This paper describes the relationship between math and music, including how musicians use mathematics to define music notations and music concepts, how modern mathematicians use math (algorithms and numbers) to create music, and how mathematicians analyze music data for patterns and etc.
Full Article: PDF
The Refugee Center Website Traffic
This paper demonstrates how I use Google Analytics, R and API to pull the traffic data from the refugee center website, how and why I apply stratified random sampling method with the website traffic data, also, how and why I employ the one-way ANOVA F-Test and Tukey-Kramer test to find the day (s) that has fewest visits.
Full Article: PDF
Presentation: PPT
Presentation: PDF (FYI: some format in this pdf are messed up because the original .PPT file is dynamic.)